

introduction
Dans cet article, nous allons parcourir le processus étape par étape d’intégration de Grafana à une instance Elasticsearch, et effectuer quelques requêtes.
Grafana
Grafana est un outil de visualisation très polyvalent. Il est capable de lire des données à partir d’une variété de sources de données et de tracer avec de nombreuses options de visualisation différentes telles que des graphiques, des jauges, des cartes du monde, des cartes thermiques, etc.
Elasticsearch
Elasticsearch est un magasin de données distribué open source pour l’analyse et la recherche de données. il utilise une structure de document basée sur JSON pour stocker et indexer les données. Il utilise une structure de données appelée index inversé pour permettre une recherche très rapide sur les données stockées. De nombreuses entreprises utilisent Elasticsearch pour optimiser leurs recherches dans leurs bases de données.
Prise en charge d’elasticsearch dans grafana
La prise en charge d’Elasticsearch dans Grafana est intéressante, l’un des principaux cas d’utilisation d’Elasticsearch est le stockage de données et de métriques d’événements.Il est naturel qu’un outil comme Grafana soit utilisé pour les visualiser.
Dans cet article, nous allons parcourir le processus étape par étape d’intégration de Grafana à une instance Elasticsearch, et effectuer quelques requêtes.
Installation de grafana et d’elasticsearch
Nous utiliserons docker pour mettre en place un environnement de test pour Grafana et Elasticsearch. Nous utiliserons les images officielles du docker disponibles sur :
https://hub.docker.com/r/grafana/grafana/
https://hub.docker.com/_/elasticsearch
Voici un fichier docker-compose très simple qui démarre Grafana, Elasticsearch .
version: '3'
Services:
grafana:
image: grafana/grafana
ports:
- 3000:3000
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.0.1
container_name: elasticsearch
environment:
- discovery.type=single-node
- http.port=9200
- http.cors.enabled=true
- http.cors.allow-origin=http://localhost:1358,http://127.0.0.1:1358
- http.cors.allow-headers=X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
- http.cors.allow-credentials=true
- bootstrap.memory_lock=true
- 'ES_JAVA_OPTS=-Xms512m -Xmx512m'
ports:
- '9200:9200'
- '9300:9300'
# elasticsearch browser
Après avoir exécuté ce fichier docker-compose à l’aide de docker-compose up -d , accédez à http://localhost:9200 pour vérifier qu’Elasticsearch est opérationnel. La sortie doit être similaire à ci-dessous.
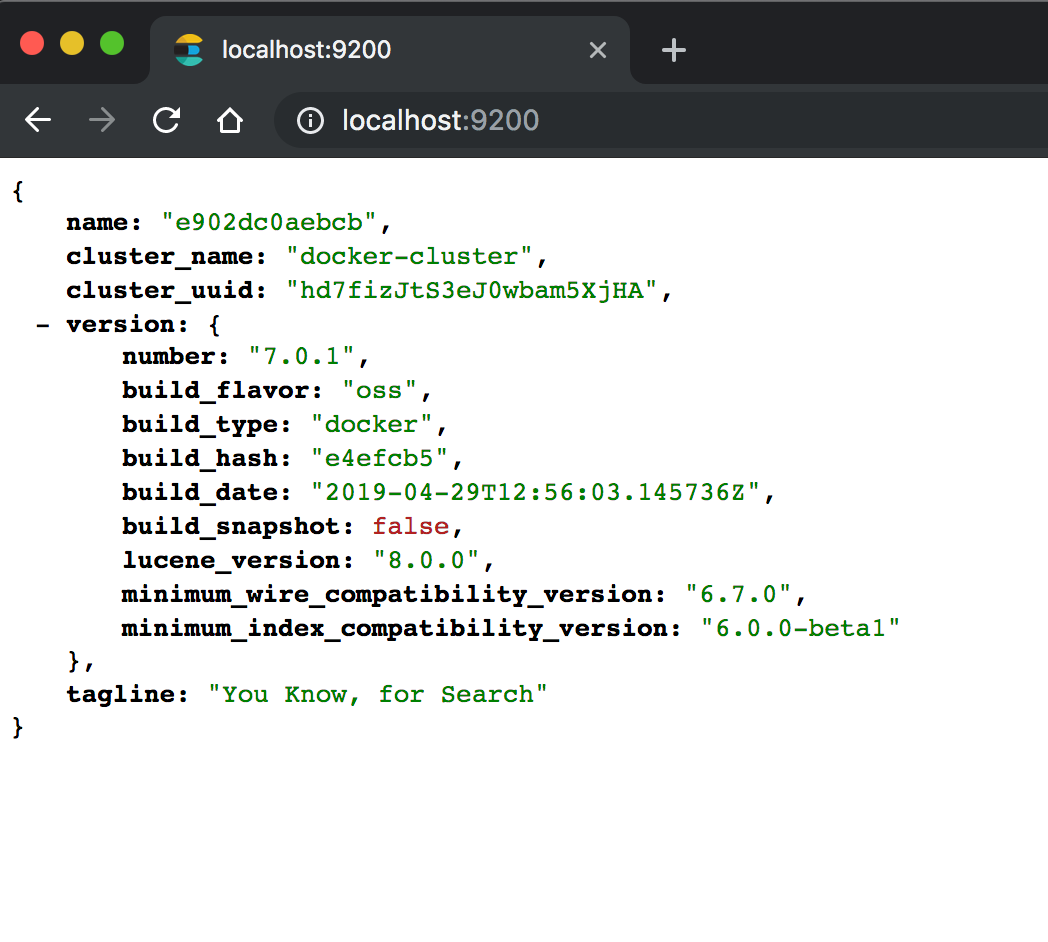
Nous vérifierons que Grafana est opérationnel en allant sur http://localhost:3000 . Les informations d’identification par défaut sont admin/admin.
Maintenant, nous allons importer les exemples de données dans Elasticsearch. Nous suivrons simplement les étapes sur le site officiel d’Elasticsearch pour charger les données logs.json dans Elasticsearch.
importer les exemples de données
Concrètement, nous exécuterons les commandes suivantes :
1. Nous allons télécharger le fichier logs.jsonl depuis les serveurs Elastic :
curl -O https://download.elastic.co/demos/kibana/gettingstarted/7.x/logs.jsonl.gz2. Décompressez le fichier :
gunzip logs.jsonl.gz3. téléchargez sur notre instance Elasticsearch :
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonlMaintenant, pour la partie passionnante. Nous allons connecter la source de données Elasticsearch à Grafana et créer des visualisations par-dessus.
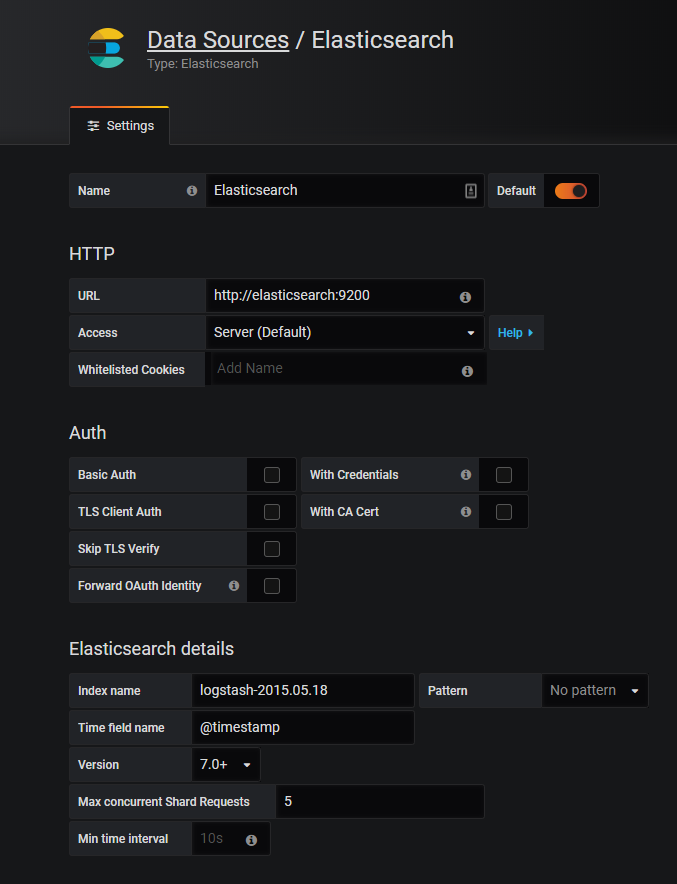
Rendez-vous sur Grafana à l’ adresse http://localhost:3000 et ajoutez une source de données de type Elasticsearch.
Remarque : l’URL sera http://elasticsearch:9200 si vous utilisez docker comme décrit dans cet article.
Pour le conteneur Grafana, l’emplacement d’Elasticsearch est http://elasticsearch:9200 et non http://127.0.0.1:9200 , comme vous pouvez vous y attendre.
La version serait 7.0+, et nous définirons le nom du champ Time comme @timestamp .
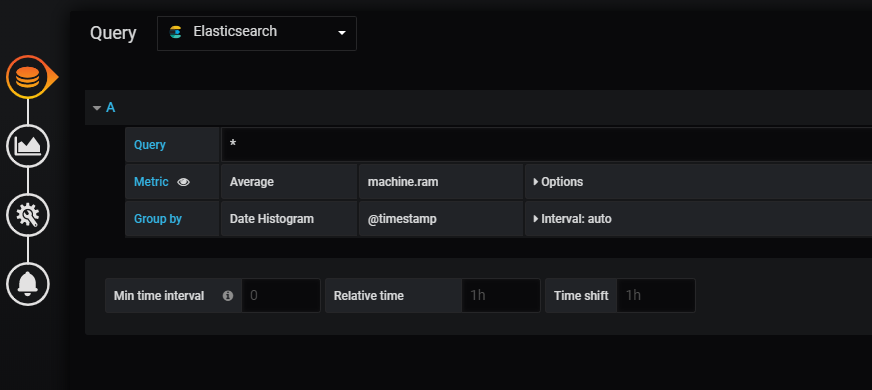
Créons maintenant un tableau de bord Grafana simple et ajoutons un graphique simple. C’est assez simple. La partie délicate consiste à configurer la source de données et à fournir la requête.
Nous allons faire une visualisation de la RAM moyenne de la machine à partir des données du journal. Dans la liste déroulante de la requête, choisissez Elasticsearch comme source de données, et nous utiliserons machine.ram comme métrique moyenne, comme indiqué ci-dessous :
Enregistrez la visualisation et nous choisirons la plage de temps personnalisée dans la case en haut à droite.
Nos données de journal contiennent des entrées du mois de mai 2015. La configuration sur cette plage horaire nous donne la visualisation suivante :
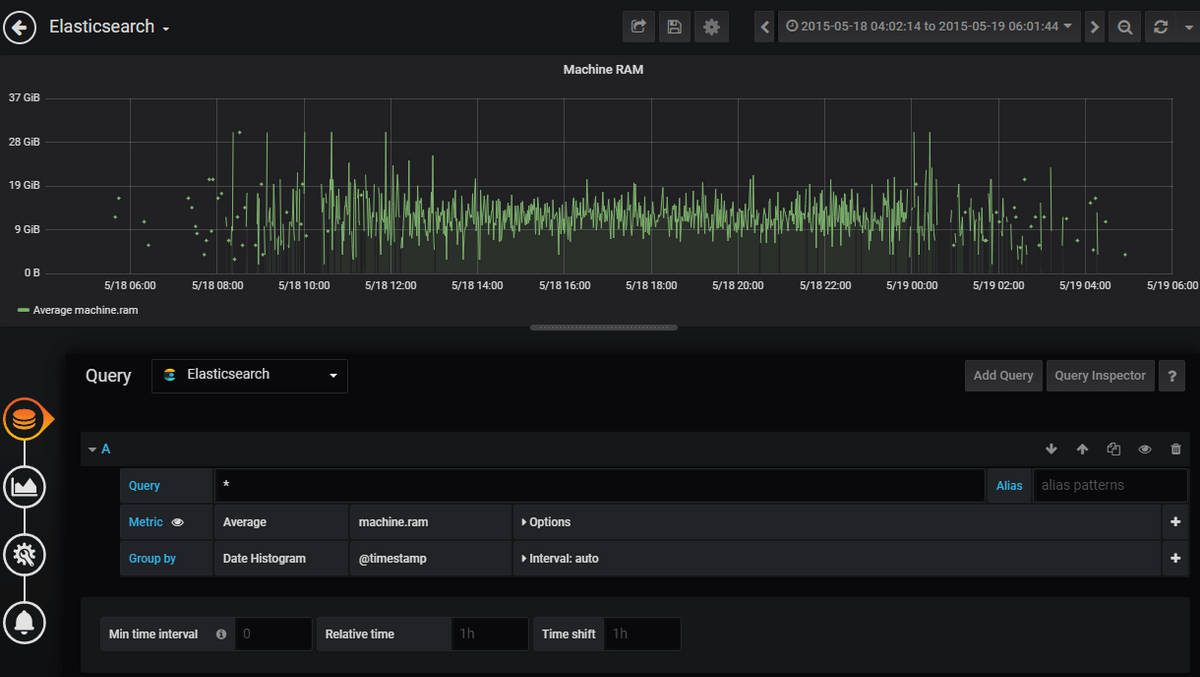
J’ajouterai la visualisation pour les octets moyens, et notre tableau de bord Grafana ressemblera à ceci :
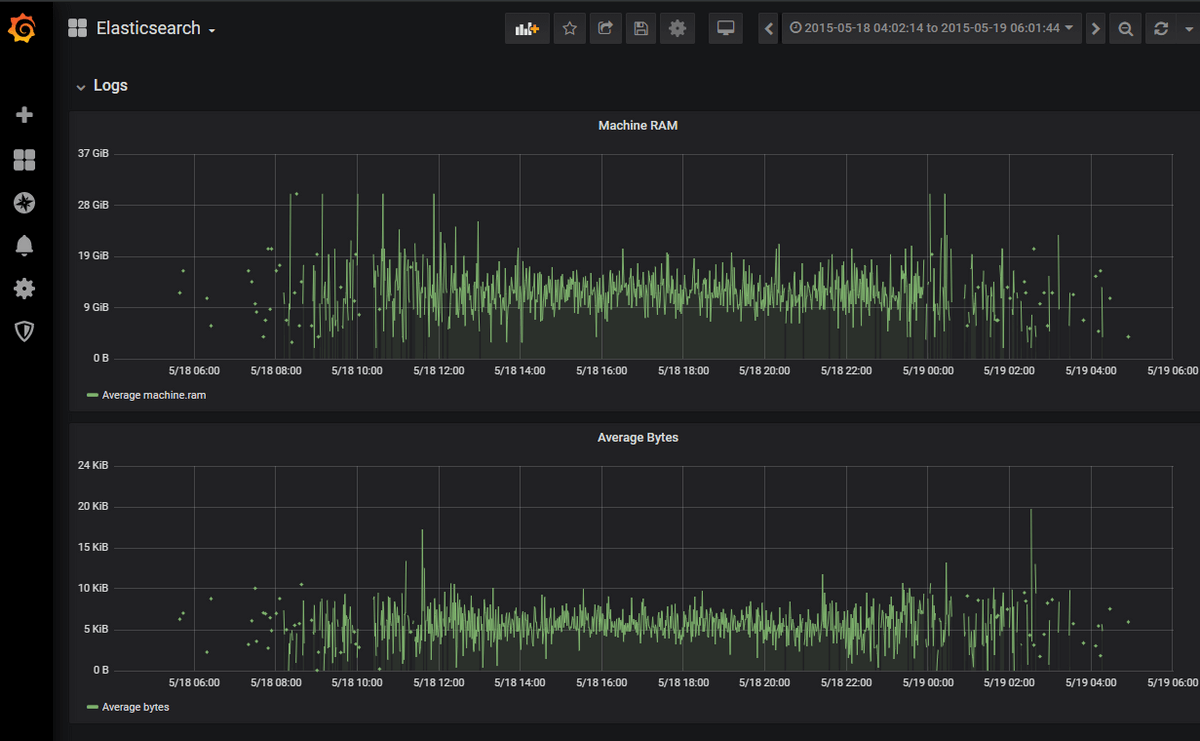
Conclusion
Merci d’avoir lu cet article, vous pouvez nous suivre sur les reseaux pour d’autres bonnes idées et informations, et vous pouvez lire notre article sur Comment surveiller votre cluster Kubernetes avec Prometheus et Grafana